本文共 1800 字,大约阅读时间需要 6 分钟。
1. 问题描述:
给定一个根为 root 的二叉树,每个结点的深度是它到根的最短距离。如果一个结点在整个树的任意结点之间具有最大的深度,则该结点是最深的。一个结点的子树是该结点加上它的所有后代的集合。返回能满足“以该结点为根的子树中包含所有最深的结点”这一条件的具有最大深度的结点
示例:
输入:[3,5,1,6,2,0,8,null,null,7,4]
输出:[2,7,4] 解释
我们返回值为 2 的结点,在图中用黄色标记。在图中用蓝色标记的是树的最深的结点。
输入 "[3, 5, 1, 6, 2, 0, 8, null, null, 7, 4]" 是对给定的树的序列化表述。 输出 "[2, 7, 4]" 是对根结点的值为 2 的子树的序列化表述。输入和输出都具有 TreeNode 类型提示:
- 树中结点的数量介于 1 和 500 之间。
- 每个结点的值都是独一无二的。
2. 思路分析:
① 首先需要读懂题目的意思,本质上求解的是叶子节点的最近公共祖先:假如根节点的左右子树高度相同那么返回的是根节点,假如左子树高度大于右子树高度,那么返回左子树中最深的那个节点,否则返回右子树中最深的那个节点,对于树的操作我们都是可以使用递归来解决的,对于这道题目来说我们可以写一个有返回值的递归,这样可以返回节点的高度来判断左右子树的高度哪个更高一点,这里使用到了一个技巧就是在方法中声明两个TreeNode类型的变量,一个是记录左子树中最深的那个节点,另外一个是记录右子树中最深的那个节点,然后在调用dfs方法的往下递归的时候修改这两个变量,这样往上层层返回的是左右子树最深的那个节点
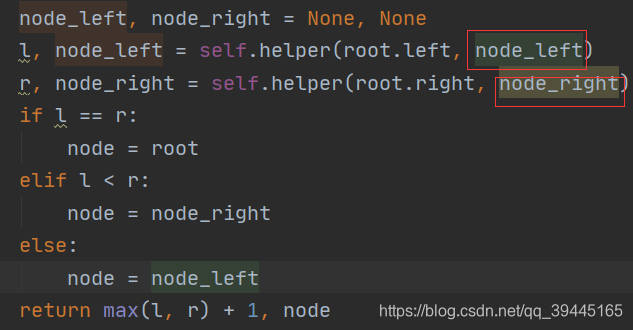
因为不像C或者Java那样传递到方法中的TreeNode引用类型变量修改层层返回之后也会跟着改变,感觉python传递进TreeNode类型之后当前那一层的node是改变的,但是在层层返回之后node不会改变,后面想到python可以返回多个类型的值,所以在调用完左右子树之后除了返回当前节点的深度之外还返回第二个变量就是当前节点的记录的最深节点,这样我们就可以利用递归在层层返回之后使用高度与node_left与node_right来更新node了,这样在层层更新返回之后node保存就是那个递归最深的那个节点
② 在方法中声明这两个TreeNode类型变量并且在方法中对于这两个的值的返回进行层层更新的技巧使很值得学习一下的,可以用来保存最深的那个节点
3. 代码如下:
class TreeNode: def __init__(self, val=0, left=None, right=None): self.val = val self.left = left self.right = rightclass Solution: def helper(self, root: TreeNode, node: TreeNode): if root is None: return 0, None # 下面的这两个变量用来记录左右子树最深的节点是很有用的, 属于一个记录最深层的节点的一个技巧(节点是引用类型的变量那么随着节点的修改而修改) node_left, node_right = None, None l, node_left = self.helper(root.left, node_left) r, node_right = self.helper(root.right, node_right) if l == r: node = root elif l < r: node = node_right else: node = node_left return max(l, r) + 1, node def subtreeWithAllDeepest(self, root: TreeNode) -> TreeNode: res = self.helper(root, None)[1] return res
转载地址:http://klgr.baihongyu.com/